TCIA数据库CT数据下载及格式转换(dcm➡️jpg)
最近需要在The Cancer Imaging Archive(TCIA)数据库下载胶质瘤CT数据,搜了一圈似乎没有很系统的下载指南,所以就写下此文记录一下~
后续还对下载的数据集数据进行了转换(dcm➡️jpg)
最近需要在The Cancer Imaging Archive(TCIA)数据库下载胶质瘤CT数据,搜了一圈似乎没有很系统的下载指南,所以就写下此文记录一下~
后续还对下载的数据集数据进行了转换(dcm➡️jpg)
参考文章:Elucidation of DNA methylation on N6-adenine with deep learning,实践文章中从不同物种中迁移学习,预测6mA位点。
对真核生物在N6DNA甲基化的研究在最近得到了很大的关注。最近的研究已经产出了大量的6mA基因组数据,但是真核生物中DNA 6mA仍然有待探索。我们提出了在真核生物中6mA DNA是稀少的,这客观上限制了现有的生物学技术对6mA位点的检测,同时,6mA复杂的调节机制也对DNA 6mA的研究造成巨大挑战。为了探索现存的6mA基因组数据以及应对这一挑战,,这里我们提出了一种基于深度学习的算法用于在单碱基(single nucleotide resolution)中预测DNA 6mA位点。并且,我们还将算法应用于三个具有代表性的模型物种中:Arabidopsis thaliana(拟南芥),Drosophila(黑腹果蝇)和Escherichia coli(大肠杆菌)。大量的实验证明我们算法的性能优于传统基于k-mer的方法。进一步的,我们的基于显著图的上下文分析显示,围绕6mA位点的感兴趣的cis-调节位点模式在传统分析中被遗漏了。我们希望我们的分析工具可以帮助我们解释6mA的调节机制,深度探索其中的功能效应。最终,我们提供了一个基于硅的全基因组预测的具有潜力的6mA位点完整的条目。
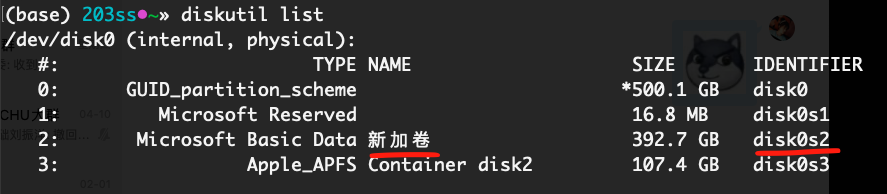
最近搞了hackintosh,装完发现硬盘是只读状态了,挂载不上。Google了一下,找到下列解决方案:
查看要挂载的盘符:
1 | diskutil list |
如图所示,根据盘名找到要挂载的盘标识符(IDENTIFIER)
在Volumes创建所要挂载的标识符的文件夹
1 | sudo mkdir /Volumes/disk0s2 |
挂载
1 | sudo mount -t ntfs -o rw,auto,nobrowse /dev/disk0s2 /Volumes/disk0s2 |
大功告成
胶质母细胞瘤(GBM)是四级胶质瘤,其总体生存期很差,大约为14个月。目前的治疗方法对该类患者而言效果并不好,因此,探索新的治疗靶点可能对于治疗GBM患者有很大的帮助。
众所周知,microRNAs(miRNAs)通过调节靶向基因调节细胞功能。最近,人卵巢癌和乳腺癌中,发现miRNA-448的表达下降。除此之外,miR-448在抑制胰腺癌的发生中发挥巨大的作用。然而,在GBM中,miR-448的作用还是未知的。
在先前的研究中,Rho相关蛋白激酶1(ROCK1)在癌症的恶性程度方面扮演着重要角色。在胃癌和骨肉瘤中,监测到了ROCK1的表达增长,并且,ROCK1加速胰腺癌和前列腺癌细胞的增长。除此之外,ROCK1促进胶质瘤细胞的侵袭,这表明ROCK1 mRNA在胶质瘤患者中具有重大的诊断意义。但是目前关于miR-448和ROCK1在GBM的关系仍是未知的。本文主要探索miR-448如何在GBM中调节细胞进程。
组织学上定义的胶质母细胞瘤(GBM)为否存在中央假栅栏坏死和微血管增生(histGBM)。根据2021年WHO中枢神经系统肿瘤分类手册将IDH野生型弥散性星型胶质瘤,包括任一的分子特征:1)TERTp突变,2)EGFR基因扩增,3)七号染色体获得与十号染色体缺失,且无论是否存在中央假栅栏坏死和微血管增生定义为分子GBM(molGBM)。本研究是为了探究histGBM与molGBM患者间的生存差异。
使用黄金分割法求极小值点。
前提:函数在所求区间为单峰函数,即存在唯一极小值点。
在本研究中,我们通过上皮肿瘤细胞的大小构建了了一个新的隔离方法,该方法通过使用生物相容性二烯烯聚合物膜携带在高流速下直径8㎛的气孔富集CTC。
脑胶质瘤是一种具有高侵袭性的脑肿瘤,高侵袭性使得患者的预后和治疗效果不佳。细胞死亡在癌症的治疗中具有好的前景。铁死亡,一种最近发现的调控细胞死亡类型,可以被诱导杀死脑胶质瘤细胞。然而,在脑胶质瘤中预测铁死亡相关基因的预后仍然难以捉摸。
本文目的是发掘GBM相关的表面组基因以及识别关键的具有发展潜力的细胞表面基因作为GBM分子标志物用于治疗。主要利用TCGA GBM RNA-Seq数据以及GTEx正常脑皮层数据识别在GBM中显著失调的表面组基因,本文还综合分析了转录组学,蛋白组学数据来区分具有高置信度的GBM表面组特征。
这篇保存一些pandas常用的命令,字符串获取的方法,以及字典列表的一些实用方法
1 | import pandas as pd |